Everyone is talking about SKILL.md, but 90% are doing it wrong. Here is the actual framework


If you've been following the AI agent space, you've seen SKILL.md pop up everywhere — Claude Code, VS Code Copilot, OpenAI Codex CLI, Cursor. But most people treat it as "just a markdown file with instructions." That is a profound underestimate of what's actually happening under the hood.
This post is the deep dive. By the end, you'll understand the architecture, the secrets that make it scale, the hidden prompting patterns that separate great skills from mediocre ones, and why this became an industry-wide open standard in under two months.
TL;DR — the 5 things most people don't know about SKILL.md
- The description field is the router. Write it like a routing rule, not a summary.
- Progressive disclosure means infinite scale. You can bundle 50 files — only the relevant ones ever load.
- Scripts cost zero tokens. Their source never enters context; only their output does.
- Claude reads its own skill files. There's no external injector — Claude uses bash to load context itself.
- It's a cross-platform open standard. Write once, run on Claude Code, Codex CLI, VS Code Copilot, Cursor — unmodified.
What problem does SKILL.md actually solve?
General-purpose AI agents are brilliant generalists. They're terrible specialists. Ask Claude Code to fill out a PDF form without guidance, and it'll hallucinate field names, guess at validation rules, and produce inconsistent output. Ask it to do the same thing with a well-crafted skill? It becomes a deterministic, reliable specialist.
Anthropic's framing is precise: building a skill is like writing an onboarding guide for a new hire. Instead of custom-building fragmented agents for each use case, you capture and share your procedural knowledge in composable, reusable form. Anthropic The new hire never forgets it. Never needs to be reminded. Loads the right chapter at the right moment.
The key insight: the bottleneck isn't model intelligence. It's context delivery.
The anatomy of a SKILL.md file
At its core, a skill is a directory. The minimum viable structure is one file:
my-skill/
└── SKILL.mdThat file has two parts: YAML frontmatter and a markdown body.
---
name: expense-report
description: File and validate employee expense reports according to
company policy. Use when asked about expense submissions,
reimbursement rules, or spending limits.
version: "2.1"
author: contoso-finance
license: Apache-2.0
---
# Expense Report Skill
## Step 1 — Gather required fields
Always ask for: employee ID, date range, cost center...
## Validation rules
- Receipts required for all items over $25
- Travel must be pre-approved via TravelDesk...The frontmatter configures how the skill runs — permissions, metadata, versioning. The markdown body tells Claude what to do. At agent startup, only the name and description fields are pre-loaded into the system prompt. Anthropic The full body stays on the filesystem until needed.
This distinction — name/description vs. full body — is the entire game.
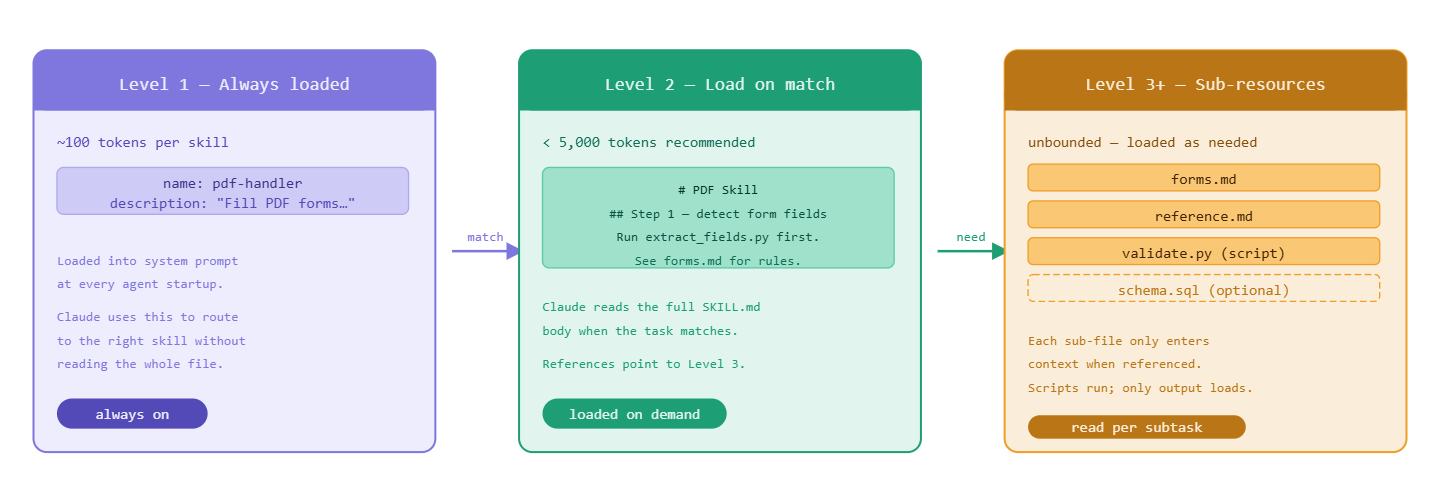
Secret #1: Progressive Disclosure is the real architecture
Most people think SKILL.md is a "big instructions file." It isn't. It's a three-level information retrieval system.
At agent startup, Claude pre-loads only the name and description of every installed skill. That's Level 1 — enough context to know when a skill is relevant, without bloating the context window. When Claude determines a skill matches the current task, it reads the full SKILL.md body. That's Level 2. If the task requires sub-specialization, Claude reads linked reference files. That's Level 3 and beyond. Because additional context is fetched via file reads rather than pre-loaded, the amount of knowledge bundled into a skill is effectively unbounded. Verdent
Microsoft's documentation for the Agent Framework captures the token economics precisely: advertising a skill costs roughly 100 tokens per skill. Loading the full SKILL.md body should ideally stay under 5,000 tokens. Reading supplementary resources happens only when required. Microsoft Learn
This means you can have a skill with a 50-page technical spec, a database schema, and multiple reference documents — and it consumes zero context tokens until it's relevant.
Secret #2: The description field IS the routing engine
This is the most underestimated secret in the entire spec. People spend hours writing perfect instructions in the SKILL.md body and three seconds writing the description. That's backwards.
Bad description:

Good description:
The SKILL.md frontmatter for a real production skill looks like this:

The 5 prompting secrets for writing great skills
1. Front-load the decision, not the knowledge
The first 3 lines of your SKILL.md body should tell Claude when to bail out, not when to proceed. "If the user is asking about X and Y is not true, stop here and respond with Z." Fail fast before loading sub-resources.
2. Use progressive references explicitly
In your SKILL.md body, always say things like: "For validation rules, read references/RULES.md. Only read this if the user is submitting a new form." Never just dump a filename — give Claude the condition for reading it.
3. Scripts are your secret weapon for determinism
Any logic that requires 100% reliability — parsing, validation, calculations, file transformations — belongs in a script, not in instructions. Write extract_fields.py and tell Claude to run it first. The instructions then operate on the structured output.
4. One skill, one domain
When the SKILL.md file becomes unwieldy, split its content into separate files and reference them. If certain contexts are mutually exclusive or rarely used together, keeping the paths separate will reduce token usage. Anthropic Resist the urge to build a "do everything" skill. pdf-read and pdf-fill are better as two separate skills than one mega-skill.
5. Build skills with Claude, not before Claude
As you work on a task with Claude, ask it to capture its successful approaches and common mistakes into reusable context and code within a skill. If it goes off track when using a skill, ask it to self-reflect on what went wrong. This process will help you discover what context Claude actually needs, instead of trying to anticipate it upfront. Anthropic
SkillsAuth is building the trust and identity layer for the Agent Skills ecosystem. Explore the marketplace at skillsauth.com.



